Какво е Generative Engine Optimization и защо вече не създаваме съдържание за Google, а за ChatGPT? Собствено проучване, за да съм в крак с най-новото и модерното.
В края на миналия век, а именно пролетта на 1999 г. започнах първата си сериозна работа. Бях студентка втори курс политология в СУ и предложението, което получих – 4 часов работен ден, когато ми е удобно, плюс достъп до компютър с интернет. А работата, Bulgaria Online (online.bg) и по-конкретно: да пълня съдържание което да се индексира и да се търси в него. Най-просто казано: копи-пействах информация в една оракълска база, предимно новини. По това време глобален лидер беше Yahoo, но и по-малко разпознаваемите AltaVIsta и Lycos.
Някъде по това време се появи и Google. Вероятно малко хора знаят, че създателите на Google предлагат технологията си на Yahoo за 1 милион долара и пичовете от Yahoo им се изсмиват и ги изпъждат. После всички знаем какво се случи.
Пак по това време за пръв път се използва и технологията за оптимизиране на резултатите на търсачките, по късно позната като Search Engine Optimization (SEO). Интересна е историята около навлизането на тази практика:
През 1997 година, рок групата Jefferson Starship забелязва, че официалният им уебсайт не се показва в резултатите на търсачките, когато фенове търсят името на групата. Свързват се с уеб експерт – според някои източници това е Боб Хейман (https://bobheyman.com/), който по-късно става един от пионерите в SEO индустрията. Причината за проблема се оказала тривиална по днешните стандарти: името „Jefferson Starship“ не се споменавало достатъчно често в текстовете на сайта, а по това време търсачките разчитали основно на съвпадения на ключови думи в съдържанието.
И така повече от 20 години SEO доминира онлайн маркетинга. А Google е category killer в търсенето.
Аз изобщо не се вълнувам от темата за маркетинга. Вълнувам се от тенденциите. От миналата година следя какво се случва при търсенето – а именно, че GPT чатботовете се използват от все повече хора вместо търсачките. Според изследване за 2024 г. за какво пълнолетните потребители използват GPTтата:
- 68% – да научат повече по дадена тема
- 62% – да открият конкретен факт
- 32% – да открият конкретен сайт
Бързо, лесно и удобно чатботът ти изсипва информация, а напоследък някои въведоха и допълнителна функция, която подпомага клетия потребител съвсем да не влага мисъл, като ти предлага допълнително каква информация може да ти даде чрез примерни въпроси.
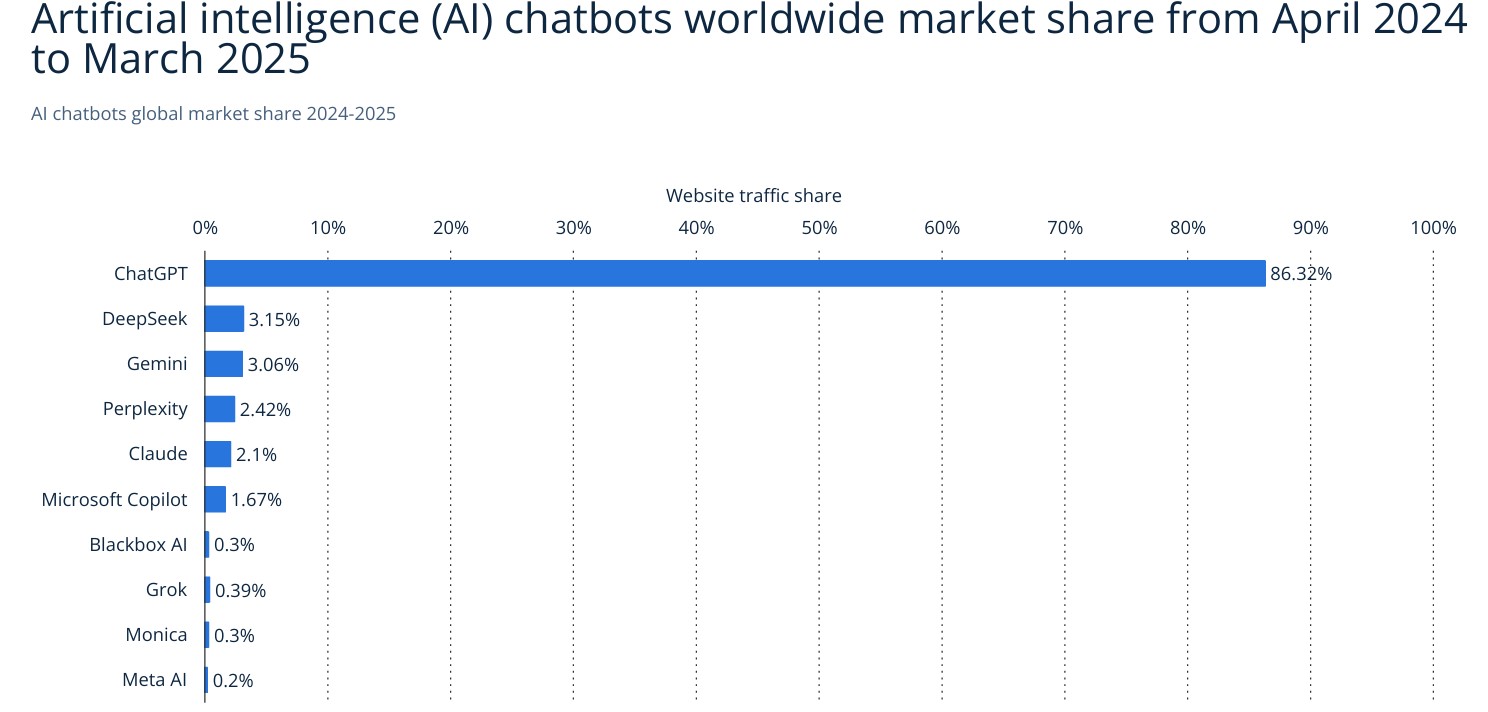
Та при чатботовете абсолютен лидер е ChatGPT. Трафика на Google падна драстично. Макар че се носят слухове, че ChatGTP всъщност “гугълва” вместо нас. От OpenAI не коментират.
Преди няколко дни в полезрението ми попадна термина GEO (Generative Engine Optimization) и реших да проверя това ли ще е SEO килъра.
GEO vs SEO: каква е разликата?
- SEO цели даден уебсайт да се изкачи на върха в търсачките.
- GEO цели създаденото съдържани в уебсайта да бъде избрано от ИИ-системата и генерирано като отговор през чатбота.
| Характеристика | SEO | GEO |
| Фокус | По-високо класиране в търсачки | Избор като отговор от ИИ |
| Формат | Текст и линкове | Мултимодално съдържание: текст, картина, звук |
| Критерий за успех | Ключови думи и оптимизация | Контекст, яснота и разговорен тон |
Освен това ИИ системите се обучават върху огромен обем данни, които не изискват регистрация като напр. Wikipedia, Reddit, Youtube. Така че присъствието в тези мрежи ще има все по-голямо значение. Големите социални мрежи като Facebook, Instagram, TikTok, LinkedIn и Х категорично забраняват да се използва информация на потребителите им за обучение на ИИ модели. Но пък от компаниите – собственици не коментират дали използват тези данни за обучение на собствените си ИИ модели. Вероятно да.
От всичко, което прочетох се опитах да обобщя как се прави „правилен” GEO:
- Вместо кратки, трябва да се използват дълги текстове, които често са под формата на въпрос (напр. вместо „слънцезащитен крем” „кой е най-ефективния крем за лице за слънцезащита?” – и отговорът съдържа информация за конкретен крем)
- Текстът трябва да е написан така, както потребителите питат – разговорно.
- Хубаво е да има колкото се може повече снимков и видеоматериал (като кратки рийлове), които разбера се са коректно alt-нати.
- Да има колкото се може повече текст, който редовно да се обновява.
В крайна сметка целта е чатбота да „изплюе“ пасаж от вашето съдържание. Големият въпрос, на който не намерих отговор е: когато все по-голяма част от маркетинговите послания се генерират от ИИ, в един момент ИИ ще ни връща това, което сам е създал. Доста опасно ми се струва.
И още нещо – заражда се нова професия: ИИ бранд анализатор (или как ИИ системите “виждат” конкретен бранд).
За написването на този материал са използвани данни от Statista и материали от Forbes, New York Times (които ми дойдоха от абонамента ми за бюлетините им) и 15 източника, които ми даде Perplexity (www.perplexity.ai) на въпрос: What is GEO (Generative Engine Optimization)? (т.е. и аз съм от тези 68%, които използват чатбот за да научат повече по дадена тема).
Лично аз ако ще използвам GPT чатбот като търсачка, предпочитам Perplexity. Най-добре ми структурира информацията и източниците, които са използвани за да се генерира отговора. Обикновено ако е нещо важно го проверявам и с ChatGPT.
Мисля, че текстът ми се получи като да го изплюе ИИ на някой друг търсещ по темата. Вие как мислите?



